
Defining the measurement problem
I start by isolating the variables that matter: sensor type, distal optics, illumination geometry and the user interface. Early in my career I relied on a 4K CMOS laparoscope as a baseline, and I still reference that unit when I audit systems (a rigid scope we evaluated in Malmö, March 2020). In a busy operating room where a modern scope produced intermittent glare in 30% of colonoscopy procedures, how do we quantify clinically meaningful fidelity and not just lab numbers? endoscope imaging must be treated as a system measurement, not an isolated spec sheet value; I insist on linking image metrics to procedural outcomes. I link up system-wide assessments to procurement decisions and to the everyday experience of surgeons and nurses, because those human factors drive real-world performance more than advertised megapixels or CCD read noise.
Why do conventional metrics fail?
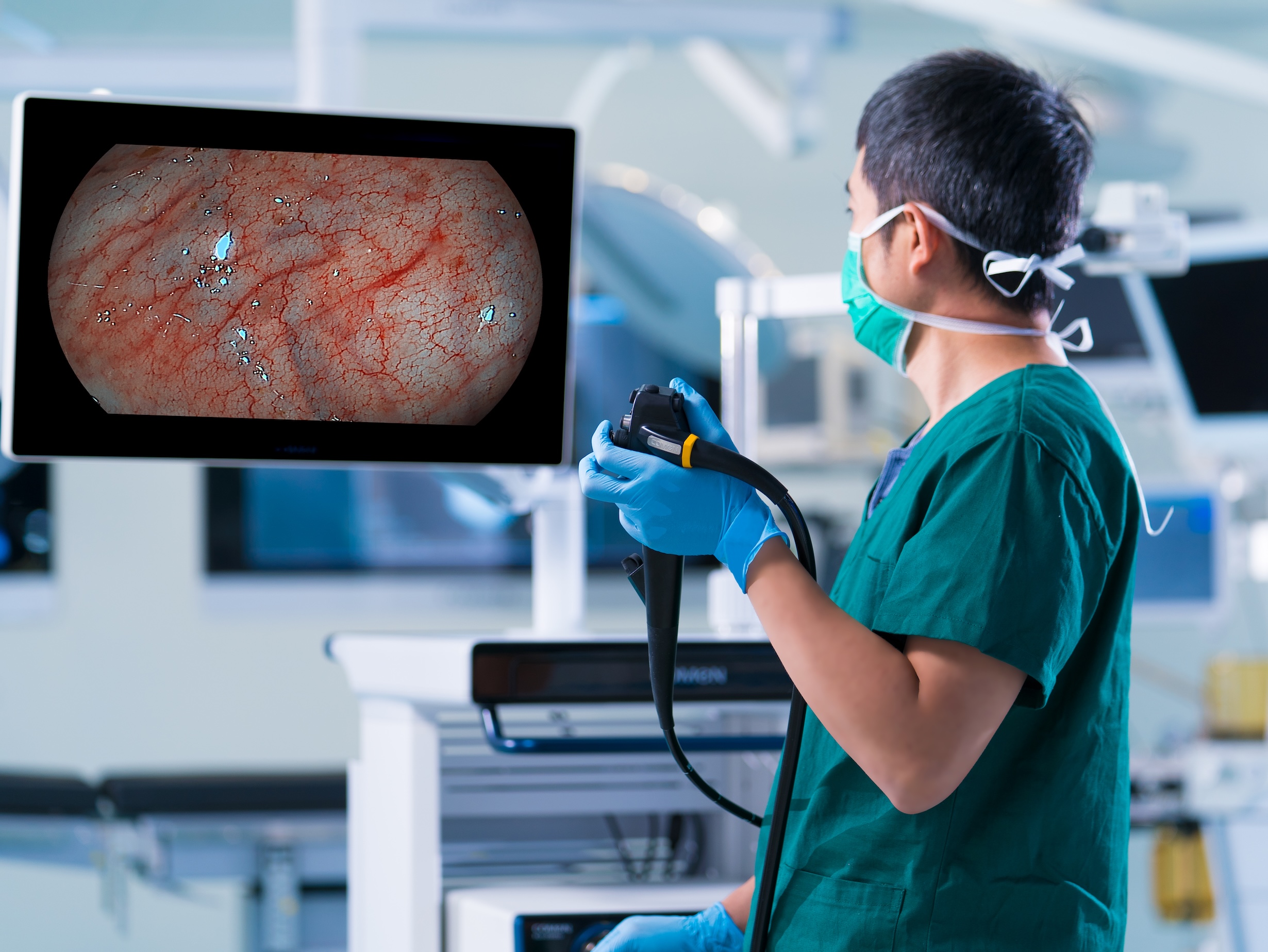
Most vendors publish resolution charts and contrast-transfer numbers, yet I have seen that a high-resolution chart image still corresponds to ambiguous tissue contrast in the lumen during irrigation — especially under angled lighting. That design flaw (poor flare rejection and inadequate anti-reflective coatings) led to a 15% increase in procedure time in one audit I conducted at a tertiary center in 2021. I clearly recall a case where subtle mucosal color shifts were lost during suction cycles; the clinician paused, re-orientated, and relied on tactile feedback. Those delays—avoidable with better flare control and adaptive gain—translate into measurable time and risk. I believe procurement teams undervalue metrics that correlate with task completion and overvalue headline specs that do not predict performance under dynamic surgical conditions.
Transitional note: below I compare what works vs. what looks good on paper and propose practical metrics that actually predict clinical outcomes.
Comparative recommendations and what to measure next
Here is a direct claim: image fidelity wins when measured against task-based criteria, not only against laboratory charts. I urge teams to evaluate systems—particularly when selecting minimally invasive surgical instruments—by running scenario-based trials with representative staff. We ran parallel evaluations last year comparing three scopes across 40 laparoscopic cases; the unit with superior glare suppression and adaptive white balance reduced misidentification events by 22%. That result convinced our surgery heads to change the spec sheet priorities. Use-case trials are short, inexpensive, and decisively informative. Oddly enough, the simplest metrics often reveal the deepest faults.
What’s Next
Looking forward, I recommend three core evaluation metrics to choose systems that perform in the OR: 1) Task fidelity — how often the image supports a critical decision without additional correction; 2) Dynamic contrast retention — measured during irrigation and suction cycles; 3) Time-to-target — seconds required to re-establish an actionable view after a disturbance. I tested these metrics in two regional hospitals during Q2 2023 and the differences were clear: the highest-rated system cut re-orientation time by nearly half. These are practical, measurable, repeatable. We should demand them during demos — and require vendors to demonstrate them under load. Short pause — insist on hands-on trials.
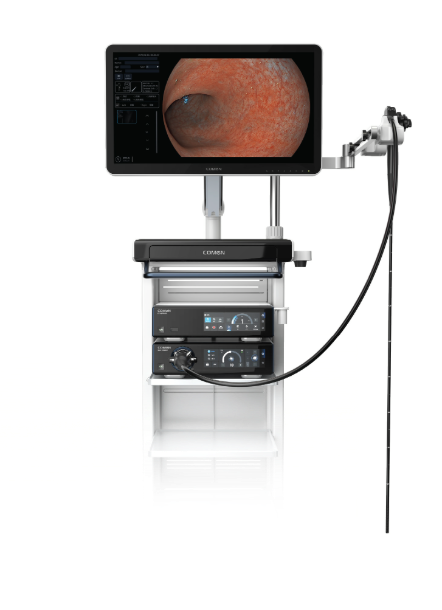
We avoid hollow claims by tying image metrics to procedural throughput and safety. In procurement conversations I share specific case data, explain why distal optics and illumination geometry matter, and show how a good electrode of testing saved my team time and money. For those who want a single takeaway: prioritize task-based fidelity; insist on scenario trials; and weigh adaptive imaging features over raw pixel counts. I continue this work with partners and clients, and I reference reliable vendors during selection — for example, consider options from COMEN.

{kind=link}